Web-WeaverDes Schockwellenreiters Webworker-Seiten |
||||||
|
Navigation
Wo bin ich?
Startseite Inhaltsverzeichnis JavaScript und HTML Keep It Simple, Stupid! Diashow MacJavaScript PopUp-Fenster Weiterleitung Multimedia SVG (1) SMIL (1) SMIL (2) XML und Webservices Was ist RSS? Wozu RSS? Amazon S3 CMS Editieren im Browser AppleScript & Python Blogger API Blogger API 2 MetaWeblog API Open Source CMS Web-Navigation Zope-Hoster Vortrags-Folien BlogTalk 1 BlogTalk 2 Zope und Plone Usability FJVD 2004 Sonstiges Browser-Shootout Dosenfleisch Dosenfleisch & Lisp Archiv 2008 Februar 2008 Januar 2008 Archiv 2007 Dezember 2007 November 2007 Oktober 2007 September 2007 August 2007 Juli 2007 Juni 2007 Mai 2007 April 2007 März 2007 Februar 2007 Januar 2007 Archiv 2006 Dezember 2006 November 2006 Oktober 2006 September 2006 August 2006 Juli 2006 Juni 2006 Mai 2006 April 2006 März 2006 Februar 2006 Januar 2006 Archiv 2005 Dezember 2005 November 2005 Oktober 2005 September 2005 August 2005 Juli 2005 Juni 2005 April 2005 März 2005 Februar 2005 |
Werbung
|
|||||
|
Was ist RSS?[Note 1]: Dieser Text versucht, zwei Fliegen mit einer Klappe zu schlagen. Einerseits soll er auch technisch nicht so versierten erklären, was RSS ist, zum anderen aber auch Programmierern ermöglichen, in eigenen Projekten RSS zu integrieren. Diese technischen Teile sind eingerückt zwischen zwei horizontalen Linien eingeschlossen und mit dem Truthahn markiert. Sie können, ohne daß das Verständnis des Resttextes leidet, übersprungen werden.
Push versus Pull Ein Besucher, der auf normalen Wege das Web abklappert, tippt URL für URL in seinem Browser oder läßt sich von Link zu Link, den er anklickt, auf seinen Reisen durch die Weite des WWW leiten. In anderen Worten, der Besucher holt sich aktiv (to pull) Daten und Content in seinen Rechner. Wenn dies auch (fast) immer funktioniert, ist dies nicht immer der beste Weg. Ein Weblogautor z.B. besucht immer wieder andere Weblogs, muß sich deren URL merken oder in seiner immer umfangreicher werdenden Bookmarksammlung verwalten, merkt bei seinen Besuchen, daß es auf dem Weblog noch nichts Neues gibt oder - bei selteneren Visiten, daß er wichtige Meldungen »verschlafen« hat. So entstehen diese täglich, öfter und gelegentlich Linklisten in den Weblogs, die dem Betreiber helfen sollen, die Übersicht nicht zu verlieren. Sicher, es gibt Hilfsmittel, wie z.B. die Update-Seiten von Weblogs.com, die ein wenig helfen. Aber gerade der eben vollzogenen Cornerturn von Weblogs.com zeigt, daß dies bei steigender Weblogzahl nicht das richtige Mittel ist, dem Chaos Herr zu werden. Es hatten sich so viele Weblogs registrieren lassen, daß oft das Scannen, ob ein Weblog geändert wurde, länger als eine Stunde dauerte und so die stündlichen Update-Listen schon bei ihrer Erstellung nicht mehr aktuell waren. Außerdem litt Weblogs.com an chronischer Überlastung, so daß die Update-Seite sehr langsam lud oder manchmal bis oft sogar überhaupt nicht zu erreichen war.
Ein anderer Weg, der - natürlich mit unterschiedlichen Techniken und Formaten, wie sollte es anders sein - schon vor einigen Jahren von Netscape und Microsoft beschritten wurde, ist der, daß der Anbieter selber informiert, wenn sich seine Seite geändert hat. Er stellt eine Datei ins Netz, die der Webbenutzer via http (dem Standardprotokoll der Browser) abrufen kann und die ihn informiert, ob sich die Seiten geändert haben. Als Format dafür bot sich XML an. Spezielle Webserver (Aggregatoren) sammeln diese Informationen und stellen sie dem Benutzer (konfigurierbar, d.h. aus den gesammelten Informationen stellt sich der Surfer seine Auswahl zusammen) zur Verfügung. Aus historischen und marketing-technischen Gründen fangen diese Server meist mit my an, wie z.B. myNetscape.com oder myUserLand.com. Der Benutzer bekommt die Daten gewissermaßen geliefert (to push) und muß nicht mehr selber nach den aktuellen Seiten suchen. Die einzelnen Seiten, die auf den Aggregatoren zusammengefaßt werden, nennt man channel. Und eigentlich sollten diese Channel nur die Überschriften der Nachrichten und eventuell eine kurze Zusammenfassung (Summary) und den Link auf die Original-Seite enthalten, nicht jedoch die Nachricht selber. (Der User soll schließlich - nachdem er sich überzeugt hat, daß die Information ihn interessieren könnte, auf die eigenen Seiten gelockt werden.) RSS Damit nun die Aggregatoren die Dateien überhaupt lesen konnten, mußte man sich auf ein gemeinsames Format einigen - und dieses Format ist RSS (Rich Site Summary).
Was steht denn nun in so einer RSS-Datei? Die Beschreibung des RSS 0.91 Standards ist realitv schwierig, denn da Netscape seinen Validator eingestellt hat, wird in der Regel schon die DOCTYPE-Deklaration weggelassen und auch die Definition der anderen Elemente mehr oder weniger streng gehandhabt. Ich gebe daher auch nur einen groben Überblick und beschreibe eine RSS 0.91-Datei so, wie sie in der Regel von den meisten Aggregatoren gelesen werden kann. Die notwendigen (required) Elemente eines Channels sind:
Es gibt noch eine Reihe von weiteren optionalen Attributen wie Copyright, Author etc. Wer das genau wissen will, kann sich hier informieren.
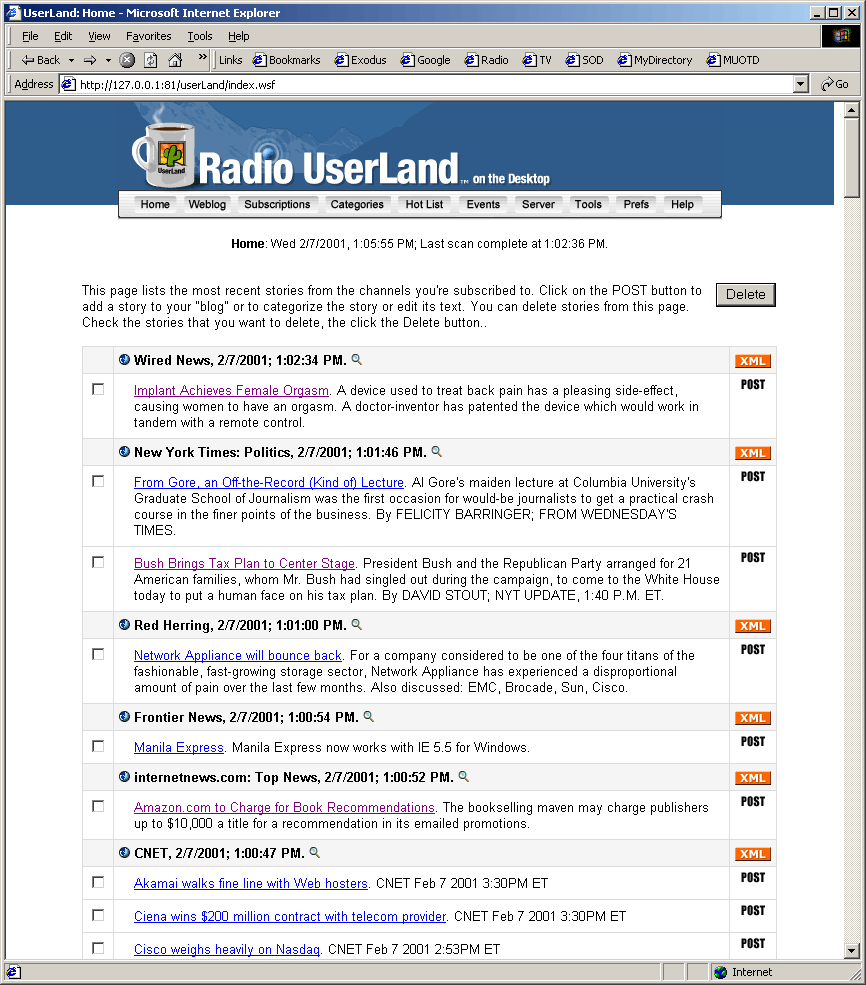
MUOTD Wer sich nun der RSS-Channels bedienen wollte, war immer auf einem der Aggregatoren im Netz angewiesen und mußte zum Lesen der Nachrichten auch weiterhin online sein. Radio UserLand besitzt nun ein sehr wertvolles Feature, wegen dem sich alleine der Download lohnt: My UserLand On The Desktop (MUOTD) (Screenshot). Das ist ein Aggregator, der auf dem Rechner zuhause läuft, auf Wunsch des Benutzers stündlich oder auch nur auf Nachfrage die abonnierten Channels abfragt und auf den Rechner des Benutzers runterlädt. Danach kann der Benutzer wieder offline gehen und in Ruhe die Nachrichten lesen und verarbeiten. Das erspart einem nicht unbeträchtliche Online-Kosten. Zusammen mit dem Weblog-Tool von Radio UserLand (das ebenfalls offline betrieben werden kann), kann man daher aus den abonnierten Channels in Ruhe sein Weblog zusammenstellen und erst nach der Fertigstellung wieder online gehen und das Weblog auf den Server runterladen. So entstehen große Teile des Schockwellenreiters und daher drängele ich auch immer, daß es RSS-Files von Euren Weblogs gibt.
Und wer erfolgreich ein RSS-Feed installiert hat, zeigt das stolz mit diesem Icon an, daß auf das RSS-File verlinkt: Links zu RSS habe ich hier gesammelt.
|
||||||
|
Letzte Änderung: 13.02.2008; 7:15:16 Uhr | © Copyright: 2000 - 2008 by Kantel-Chaos-Team | Kontakt: der@schockwellenreiter.de |
||||||


{kind=link}